Analysis of Variance (ANOVA) is a powerful statistical technique used to compare means across multiple groups. One of the most commonly used forms of ANOVA is the one-way ANOVA, which helps determine whether there are statistically significant differences between the means of three or more independent groups. In this article, we will explore the concept of one-way ANOVA, discuss its importance, and provide a detailed example using R.
What is One-Way ANOVA?
One-way ANOVA is a method used to compare the means of three or more independent groups to see if at least one group mean is different from the others. It extends the t-test to more than two groups and helps avoid the increased risk of Type I error associated with multiple pairwise comparisons.
When to Use One-Way ANOVA?
One-way ANOVA is appropriate when
You have three or more independent groups. The data is continuous and approximately normally distributed within each group. The variances across groups are roughly equal (homogeneity of variances).
Hypotheses in One-Way ANOVA
The one-way ANOVA involves two hypotheses:
Null Hypothesis (H0): All group means are equal
Alternative Hypothesis (H1): At least one group mean is different from the others.
Assumptions of One-Way ANOVA
Normality: The data in each group should be approximately normally distributed.
Independence: The observations in each group should be independent of each other.
Homogeneity of Variances: The variances of the groups should be equal (this can be checked using Levene’s test).
ANOVA Table and F-Statistic
The one-way ANOVA produces an ANOVA table, which includes the following components:
Between-group variability: Variability due to the differences between group means.
Within-group variability: Variability within each group.
F-Statistic: The ratio of between-group variability to within-group variability.
A larger F-statistic indicates a greater likelihood that there is a significant difference between group means.
Example in R
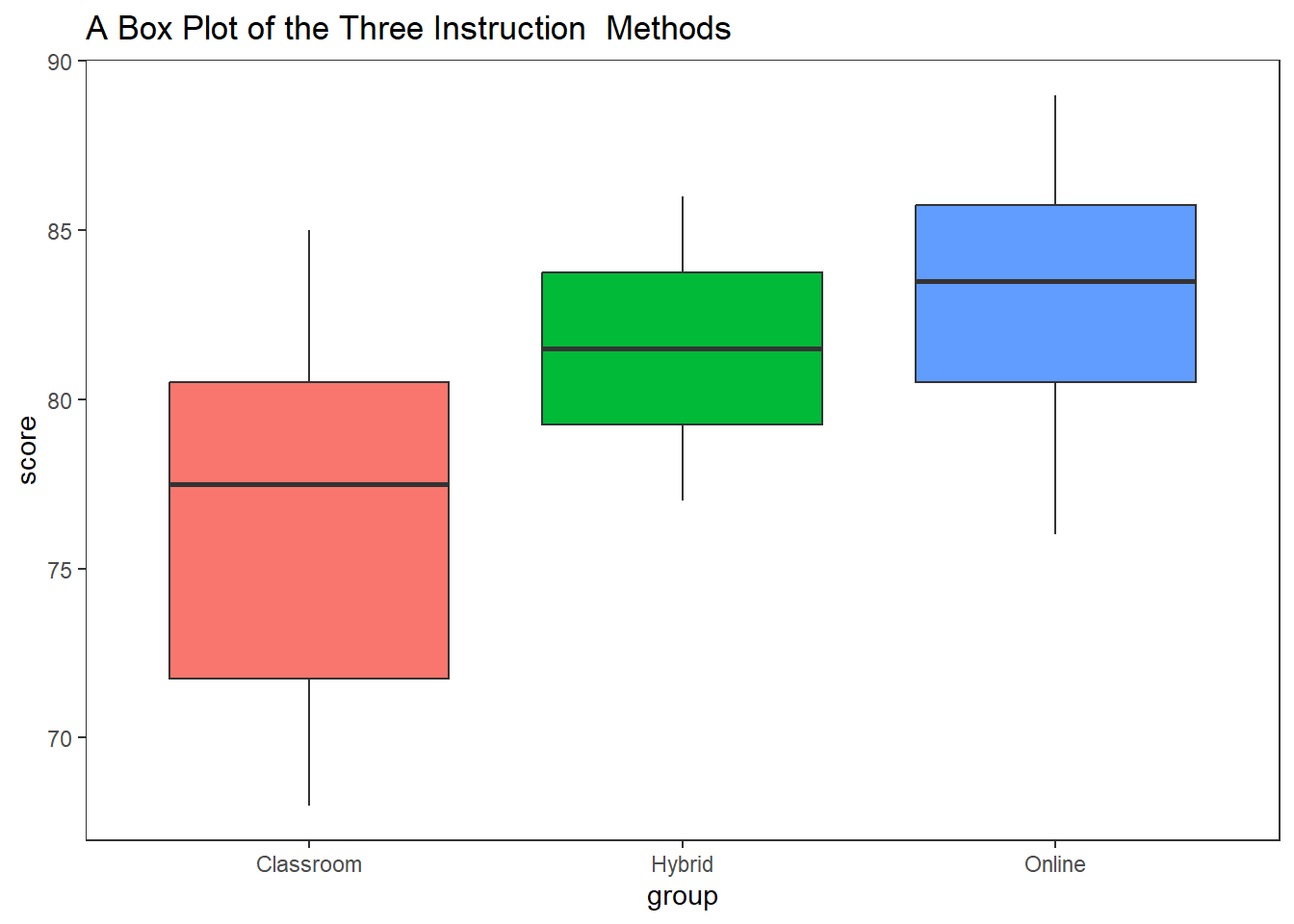
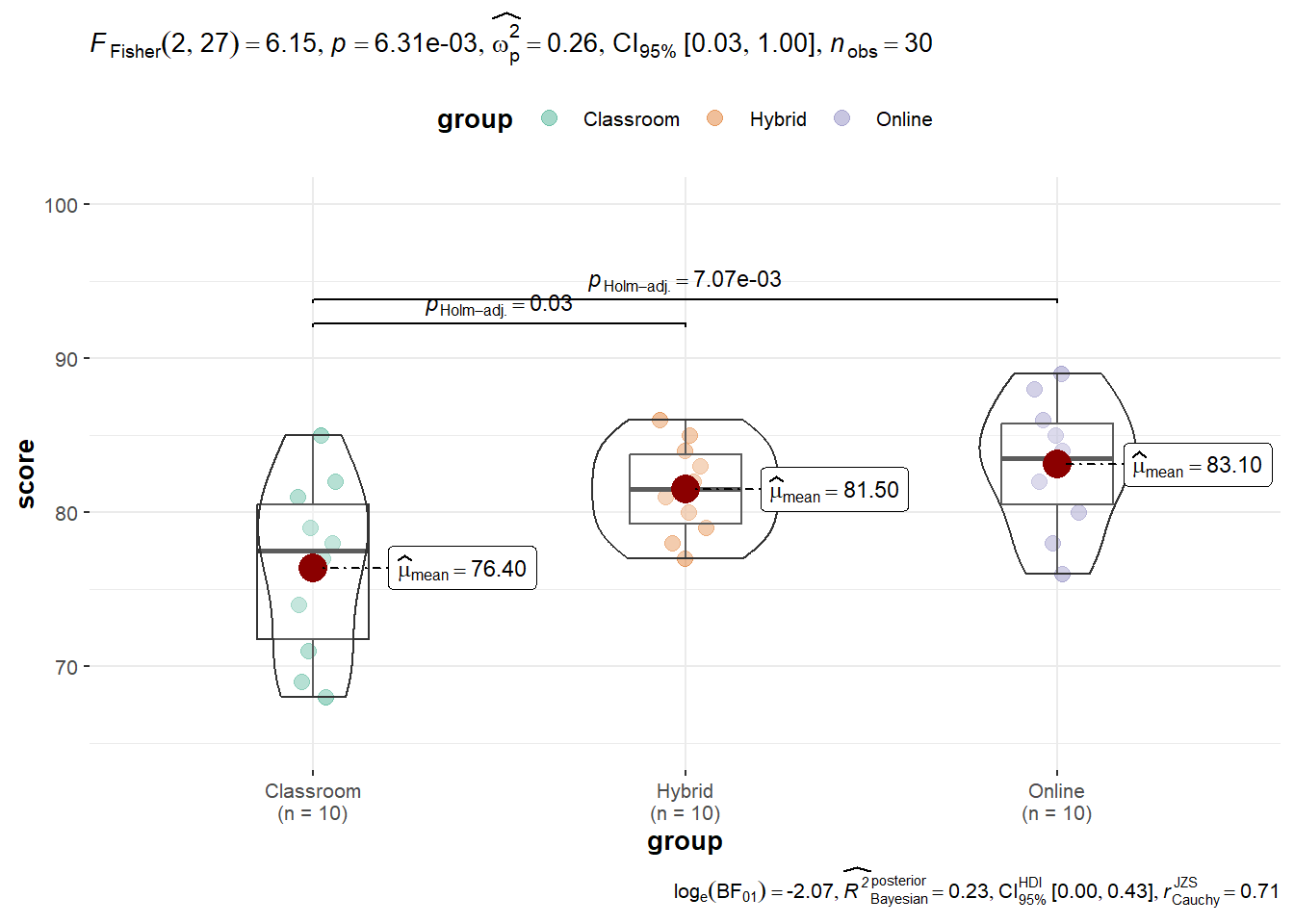
Let’s go through a practical example to understand how to perform a one-way ANOVA in R. Suppose we have three groups of students who received different types of instruction (Classroom, Online, Hybrid), and we want to test if there is a significant difference in their test scores.
# Perform one-way ANOVAanova_result<-aov(score~group, data =scores)# Print the resultsummary(anova_result)
Df Sum Sq Mean Sq F value Pr(>F)
group 2 244.9 122.43 6.147 0.00631 **
Residuals 27 537.8 19.92
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Since the p-value (0.00631) is less than the significance level (typically 0.05), we reject the null hypothesis. This means there is enough evidence to conclude that there is a significant difference in test scores between at least one pair of the groups.
Post-Hoc Analysis
If the one-way ANOVA indicates a significant difference, we often conduct a post-hoc analysis to determine which specific groups differ. A common post-hoc test is Tukey’s Honest Significant Difference (HSD) test.
Code
# Perform Tukey's HSD testtukey_result<-TukeyHSD(anova_result)# Print the resultprint(tukey_result)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = score ~ group, data = scores)
$group
diff lwr upr p adj
Hybrid-Classroom 5.1 0.1512763 10.048724 0.0424198
Online-Classroom 6.7 1.7512763 11.648724 0.0064475
Online-Hybrid 1.6 -3.3487237 6.548724 0.7052251
Cohen (1992) (“cohen1992”) applicable to one-way anova, or to partial eta / omega / epsilon squared in multi-way anova.
ES < 0.02 - Very small
0.02 <= ES < 0.13 - Small
0.13 <= ES < 0.26 - Medium
ES >= 0.26 - Large
The difference is in the three instruction method is large.
Non Parametric Test verson of One Way Anova
If the data is not normally distributed then we use the non parametric test known as Kruskal-Wallis Test
Example
Code
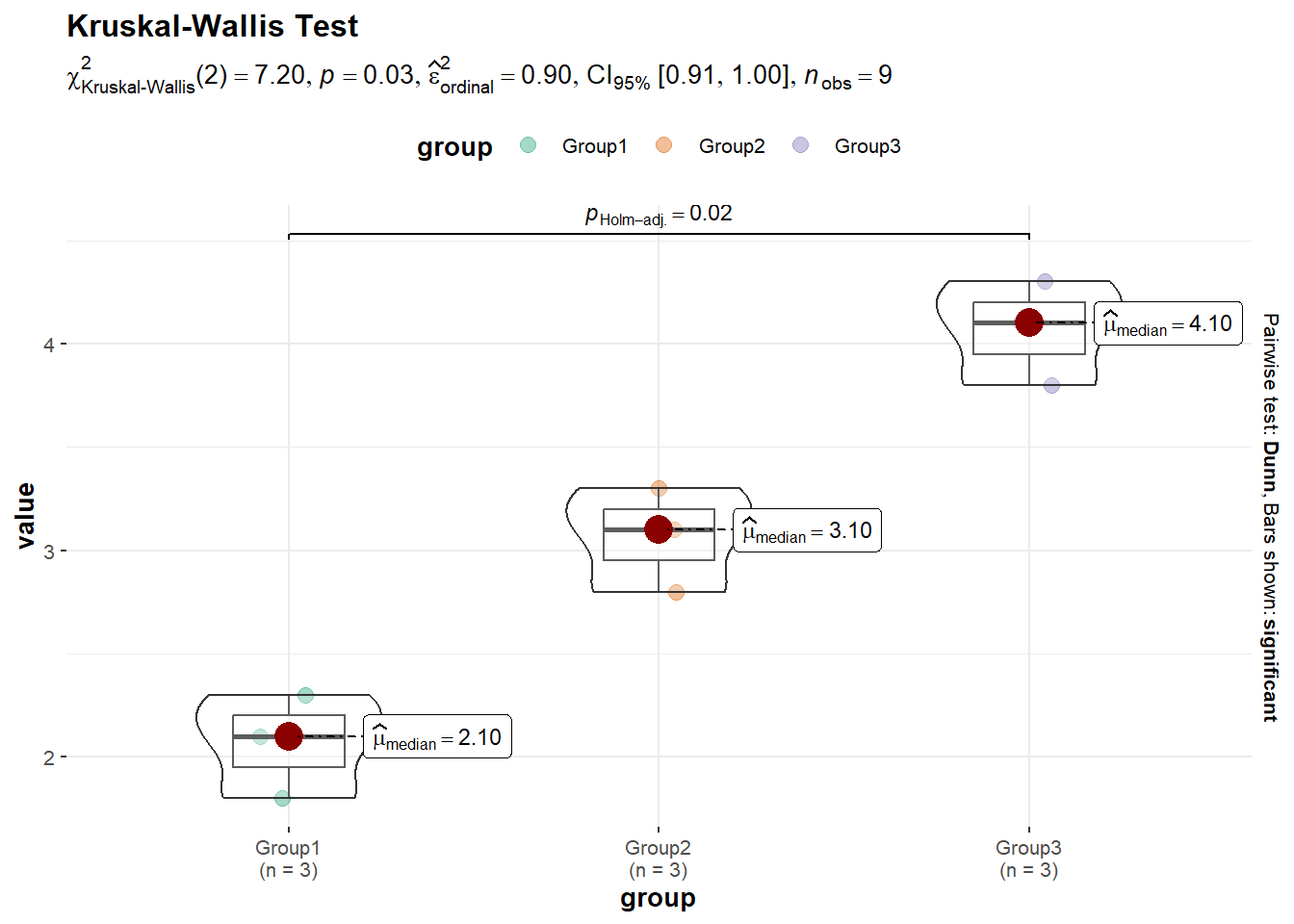
# Sample datagroup1<-c(2.1, 2.3, 1.8)group2<-c(3.1, 3.3, 2.8)group3<-c(4.1, 4.3, 3.8)# Combine data into a data framedata<-data.frame( value =c(group1, group2, group3), group =factor(rep(c("Group1", "Group2", "Group3"), each =3)))#Assuming the data is not normally distributed# Perform the Kruskal-Wallis Testkruskal.test(value~group, data =data)
Kruskal-Wallis rank sum test
data: value by group
Kruskal-Wallis chi-squared = 7.2, df = 2, p-value = 0.02732
p value <-05 indicates that there is significant difference between the three groups
Kruskal-Wallis Post Hoc Test
Code
library(FSA)# Perform post hoc pairwise comparisons using the Dunn testdunn_test_result<-dunnTest(value~group, data =data, method ="holm")print(dunn_test_result)
One-way ANOVA is an essential statistical tool for comparing the means of three or more independent groups. Always check the assumptions of normality, independence, and homogeneity of variances before performing the test to ensure valid conclusions.
Understanding and correctly applying one-way ANOVA can significantly enhance your data analysis skills, enabling you to make informed decisions based on your data. Happy analyzing!